Une grammaire des graphiques avec ggplot2
Le module ggplot2 du langage R a la séduisante caractéristique de s’appuyer sur une réflexion théorique de construction des graphiques.
Nous en aborderons ici l’aspect pratique. En revanche, la grammaire des graphiques élaborée par le statisticien Leland Wilkinson ne sera pas étudiée dans ce billet.
1. Un substrat théorique : la grammaire des graphiques
Je ne m’apesantirai pas sur le pourquoi et le comment choisir R et ggplot2, Internet est là pour ça. Je ne ferai pas non plus une initiation à R, d’autres l’ont fait bien mieux que ce dont je ne serai jamais capable.
Je voudrais m’attaquer tout de suite au coeur du sujet : faire des graphiques de gestion de manière raisonnée. On a déjà évoqué ce sujet dans le billet Les graphiques selon Stephen Few. On y a abordé la question de la diversité de représentation des mêmes données, et de quelle manière cela pouvait en influencer la compréhension.
On va continuer ici sur le sujet, mais au travers de l’outil ggplot conçu par Hadley Wickham qui met en oeuvre la grammaire des graphiques de Wilkinson :
« La grammaire des graphiques [de Wilkinson] invite l’utilisateur à repenser sa manière de concevoir un graphique en associant variables (données), paramètres graphiques (esthétiques) et formes géométriques, puis en complexifiant progressivement son graphique (coordonnées, échelles, facettes, étiquettes, légendes, thèmes…). »
Extrait de l’exposé de Joseph Larmarange réalisé pour les Rencontres de statistique appliquée, Ined, 18 juin 2018
2. Une construction par couches avec ggplot2
2.1 Approche générale
Donc on a lancé R (ou Rstudio ou Rcommander par exemple). La commande pour installer le module ggplot2 sur son poste de travail est simplement :
install.packages("ggplot2")
Une fois réalisé sur le poste, on n’aura plus à y revenir. En revanche, à chaque nouvelle session R, il faudra, si on veut l’utiliser, penser à charger le module ggplot2 avec :
library(ggplot2)
Maintenant, pour réaliser un graphique avec ggplot, il faut le penser en plusieurs étapes : cela débute avec l’appel de la fonction ggplot(). Mais la suite peut prendre deux formes, toutes basées sur la notion de couches additives.
Soit on considère le graphique comme un ensemble ayant a minima des données brutes suivi d’une couche sur le type de représentation (géométrie) en y précisant le lien avec les données (mapping). Cela peut être éventuellement complété de couches supplémentaires, ce qui donnera quelque chose de ce type :
ggplot(data = <DATA>) + <GEOM>(mapping = aes(<MAPPINGS>)) + <LAYERS>
Soit on approche le graphique comme un ensemble mettant en relation (mapping) des données et les paramètres graphiques (esthétique avec aes() pour aesthetic), suivi de la couche précisant le type de représentation à utiliser (géométrie) et d’éventuelles couches complémentaires. Ce qui se représente comme suit :
ggplot(data = <DATA>, mapping = aes(<MAPPINGS>)) + <GEOM> + <LAYERS>
ce qu’on trouve aussi dans des articles ou ouvrages, de manière plus concise mais moins pédagogique, sous cette forme toute aussi acceptable :
ggplot(<DATA>, aes(<MAPPINGS>)) + <LAYERS>
Pour la suite de ce billet, je vais suivre la formulation :
ggplot(data = <DATA>, mapping = aes(<MAPPINGS>)) + <GEOM> + <LAYERS>
Une petite précision par ailleurs. Comme on est sous R, il est possible de stocker un graphique créé avec ggplot2 dans une variable, en utilisant la flèche d’assignation. Des nouvelles couches peuvent ensuite être ajoutées à l’objet stocké.
p <- ggplot(...) + couches
p <- p + nouvelles_couches
2.2 Un premier exemple
Reprenons. Le graphique va être constitué par couches successives. Voici les premières :
- d’abord l’ensemble des données brutes,
- ensuite un ensemble de projection graphique (aesthetic mapping) pour lier ces données aux propriétés visuelles,
- une couche de géométrie (ou plusieurs) décrivant comment représenter les données (geom) : histogramme, nuage de points, lignes, diagramme barres, etc.,
- une couche pour les titre et sous-titre, les étiquettes, etc. (labs),
- des transformations statistiques (stats), si nécessaire, pour l’obtention du graphique final.
Voici ce que cela peut donner, étant précisé qu’on obtient ici un graphique vraiment basique :
# chargement de la bibliothèque graphique
library(ggplot2)
# constitution du jeu de données (source INSEE)
deces <- c(0.5, 0.9, 7.7, 10.1, 18.3, 62.6)
age <- c("00-24", "25-44", "45-64", "65-74", "75-84", "85 et +")
mortalite <- data.frame(age,deces)
# les couches essentielles de constitution d'un graphique
ggplot(data=mortalite, mapping=aes(age, deces)) + geom_bar(stat = "identity")
Ce qui affiche :

3. Première étape : définir les données brutes
3.1 Collecter les données nécessaires
Prenons un exemple issu des données fournies dans le rapport sur «Les dépenses de santé en 2019» de la DREES. Nous allons nous intéresser à la consommation de soins et de biens médicaux (CSBM, tableau 1 page 11). Les données que nous utilisons sont :
- les années (de 2010 à 2019),
- les dépenses hospitalières (privé comme public), en millions d’Euros (M€),
- les dépenses dites ambulatoires (qui comprennent les soins de ville, les médicaments, les transports sanitaires et, enfin, les autres biens médicaux comme les prothèses, l’optique etc.), en M€.
Ce qui nous donne en R :
annees <- c("2010", "2011", "2012", "2013", "2014", "2015", "2016", "2017", "2018", "2019")
hopital <- c(80316, 82461, 84567, 86688, 89060, 90430, 92320, 93848, 94887, 97127)
ambulatoire <- c(93168, 95606, 97229, 98552, 101154, 102532, 104827, 106688, 108861, 110908)
Nous constituons notre tableau de données brutes avec R :
csbm<-data.frame(annees, hopital, ambulatoire)
Il se présente donc sous forme d’un tableau de 10 lignes et 3 colonnes :
annees hopital ambulatoire
2010 80316 93168
2011 82461 95606
2012 84567 97229
2013 86688 98552
2014 89060 101154
2015 90430 102532
2016 92320 104827
2017 93848 106688
2018 94887 108861
2019 97127 110908
3.2 La nécessité de données bien formées
Mais ce jeu de données n’est pas bien formé au sens de Wickham, c’est-à-dire qu’il n’est pas structuré pour réaliser une analyse de données (voir l’article «Tidy data» paru dans le Journal of Statistical Software d’août 2014).
Cette partie est souvent occultée dans les articles ou les ouvrages, car on y utilise des jeux de données déjà constitués et (habilement) bien formés.
Disons qu’intuitivement cela revient à se demander ce que l’on veut afficher. Ici, il s’agit d’obtenir une vision des dépenses de santé par année, dépenses qui peuvent être hospitalières ou ambulatoires. Cette approche nous donne alors :
depenses <- c(80316, 82461, 84567, 86688, 89060, 90430, 92320, 93848, 94887, 97127, 93168, 95606, 97229, 98552, 101154, 102532, 104827, 106688, 108861, 110908)
annees <- c("2010", "2011", "2012", "2013", "2014", "2015", "2016", "2017", "2018", "2019", "2010", "2011", "2012", "2013", "2014", "2015", "2016", "2017", "2018", "2019")
origine<-c("hopital", "hopital", "hopital", "hopital", "hopital", "hopital", "hopital", "hopital", "hopital", "hopital","ambulatoire","ambulatoire","ambulatoire","ambulatoire","ambulatoire","ambulatoire","ambulatoire","ambulatoire","ambulatoire","ambulatoire" )
csbm<-data.frame(annees, depenses, origine)
J’ai maintenant un jeu de 20 lignes et 3 colonnes :
annees depenses origine
2010 80316 hopital
2011 82461 hopital
2012 84567 hopital
2013 86688 hopital
2014 89060 hopital
2015 90430 hopital
2016 92320 hopital
2017 93848 hopital
2018 94887 hopital
2019 97127 hopital
2010 93168 ambulatoire
2011 95606 ambulatoire
2012 97229 ambulatoire
2013 98552 ambulatoire
2014 101154 ambulatoire
2015 102532 ambulatoire
2016 104827 ambulatoire
2017 106688 ambulatoire
2018 108861 ambulatoire
2019 110908 ambulatoire
Si nous tapons :
ggplot(data = csbm)
il s’affiche un graphique vide de tout contenu.
4. Deuxième étape : la liaison (ou mapping) entre données brutes et données à visualiser (l’esthétique)
Attaquons maintenant l’étape de projection graphique (mapping) pour lier ces données aux attributs esthétiques (aes).
Nous allons faire très simple d’abord, en demandant que les années soient sur l’axe des x, et les dépenses de santé sur l’axe des y. C’est le degré zéro de l’esthétique sous ggplot.
aes(x=annees, y=depense))
On a donc les données, l’esthétique, il ne reste plus qu’à projeter tout ça et l’afficher. La commande est la suivante :
ggplot(data = csbm, mapping = aes(x=annees, y=depenses))
et nous obtenons :

La grille sur laquelle on doit positionner les données est donc bien en place. Mais on n’a pas encore défini de quelle manière on veut voir représenter les données. C’est l’étape suivante.
5. Troisième étape : la géométrie ou la spécification du type de représentation souhaité
Dans notre exemple, nous souhaitons d’abord afficher les dépenses sous forme de point. Pour ce faire on ajoutera simplement la couche geom_point(). La commande ggplot sera alors :
ggplot(data = csbm, mapping = aes(x=annees, y=depenses)) + geom_point()
Nous avons maintenant l’affichage :
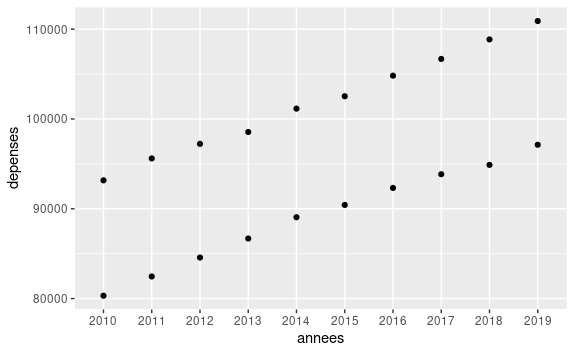
Si on a bien les dépenses hospitalières et ambulatoires sur le graphique, on ne les distingue pas visuellement. Cette distinction se situe au niveau de la couche d’esthétique. Elle peut se faire de diverses manières : par la couleur (colour=), la forme (shape=), etc. Ici on choisit de distinguer l’origine des dépenses par la couleur :
ggplot(data = csbm, mapping = aes(x=annees, y=depenses, colour=origine)) + geom_point()
Soit maintenant :

Mais imaginons que je ne veuille pas des points, mais des barres. Il me faudra changer un paramètre d’esthétique (fill=) et la couche de géométrie (geom_bar()). La commande deviendra :
ggplot(data = csbm, mapping = aes(x=annees, y=depenses, fill=origine)) + geom_bar(stat="identity")
Ce qui donne :
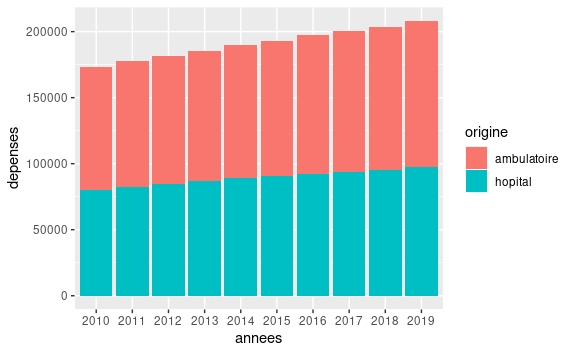
6. La formulation dépend du problème à résoudre.
Nous avons vu par l’exemple précédent que la projection esthétique (mapping) et la géométrie sont étroitement liées. La formulation que nous avons jusqu’à présent adoptée,
ggplot(data = <DATA>, mapping = aes(<MAPPINGS>)) + <GEOM> + <LAYERS>
les distingue, ce qui était intéressant pour montrer les différentes étapes de constitution d’un graphique. Mais, du fait de l’imbrication entre la projection esthétique et la géométrie, il est plus rationnel d’adopter cette formulation :
ggplot(data = <DATA>) + <GEOM>(mapping = aes(<MAPPINGS>)) + <LAYERS>
Par exemple, cette instruction :
ggplot(data = csbm, mapping = aes(x=annees, y=depenses, colour=origine)) +
geom_point()
devient :
ggplot(data = csbm) +
geom_point( mapping = aes(x=annees, y=depenses, colour=origine))
Mais on peut aussi l’écrire :
ggplot(data = csbm, mapping = aes(x=annees, y=depenses)) +
geom_point(aes(colour=origine))
et pour le diagramme barre correspondant :
ggplot(data = csbm, mapping = aes(x=annees, y=depenses)) +
geom_bar(aes(fill=origine), stat="identity")
En fait, la formulation va aussi dépendre du problème à résoudre. Dans l’exemple suivant, il apparait ainsi naturel de séparer le mapping de la géométrie, car la construction du graphique voulu le nécessite.
Nous allons utiliser les chiffres fournis par l’INSEE dans son analyse « Avec un excédent de mortalité de 2 % entre début mars et mi-avril, la Bretagne est une des régions les moins touchées ». On l’avait déjà abordée dans le billet précédent.
Sont données par tranche d’âges la répartition par sexe des personnes domiciliées en Bretagne et décédées entre le 2 mars et le 19 avril 2020, soit :
| tranche d’âges | répartition décès féminins | répartition décès masculins |
|---|---|---|
| 00-24 ans | 0,5 % | 0,6 % |
| 25-44 ans | 0,9 % | 2,7 % |
| 45-64 ans | 7,7 % | 13,7 % |
| 65-74 ans | 10,1 % | 21,1 % |
| 75-84 ans | 18,3 % | 22,9 % |
| 85 ans ou + | 62,6 % | 39,0 % |
On utilise dans cette construction la notion de facette (facet_draw()) à la place de l’esthétique (de type colour = ou shape=) pour distinguer le comportement des données attachées respectivement aux femmes et aux hommes. L’idée, en effet, est de pouvoir comparer les taux respectifs de mortalité des hommes et des femmes en réalisant un graphique pour chacun, côte à côte.
Bien sûr, les données ont été transformées pour être bien formées, comme on le constate dans les instructions R qui suivent.
# chargement de la bibliothèque graphique
library(ggplot2)
# constitution des données (source INSEE)
deces <- c(0.5, 0.9, 7.7, 10.1, 18.3, 62.6,
0.6, 2.7, 13.7, 21.1, 22.9, 39)
sexe <- c("f","f","f","f","f","f","h","h","h","h","h","h")
age <- c(rep(c("00-24", "25-44", "45-64", "65-74", "75-84", "85 et +"),2))
mortalite <- data.frame(age,deces,sexe)
# On construit la base graphique sans géométrie
base <- ggplot(data=mortalite, mapping=aes(age, deces))
# On étiquette les axes, on donne un titre, etc.
base <- base + labs(title = "Décès survenus entre le 2 mars et le 19 avril 2020",
subtitle = "de personnes domiciliées en région Bretagne",
x = "tranches d'âge",
y = "Répartition en % des décès",
caption = "Données : INSEE 2020 - Graphique : Konk Gwin")
# On répartit par sexe (facet_wrap())
labels <- c( f = "2 609 femmes décédées durant la période",
h = "2 432 hommes décédés durant la période")
base <- base + facet_wrap(~sexe, ncol = 2,labeller=labeller(sexe = labels))
# On crée le diagramme barre (geom_bar())
base <- base+geom_bar(stat = "identity")
# On agrandit l'axe des y pour écrire les % au dessus des barres
base <- base + expand_limits(y=65)
# on inscrit les pourcentages de décès au dessus des barres
base <- base + geom_text(aes(label = paste(deces,"%")), size=3, vjust=-.3)
# et on affiche le tout
print(base)
Voici le graphique obtenu :
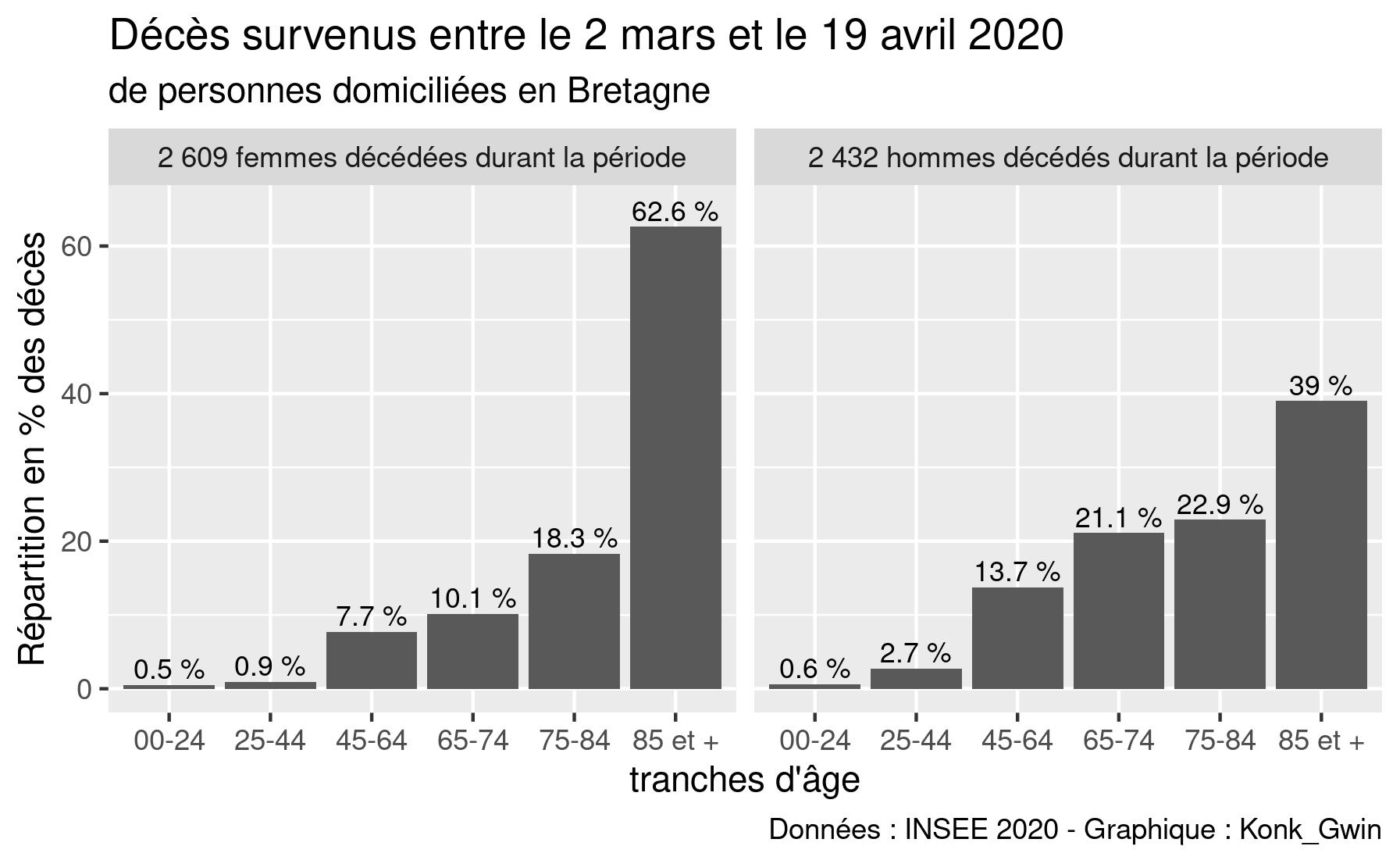
Il est clair ici que les Bretonnes ont un sacré système immunitaire ou une bien meilleure hygiène de vie que nous autres, pauvres hommes. La différence (onze points !) est surtout sensible pour la tranche 65-74 ans.
En comparant ce graphique avec la représentation choisie par l’INSEE figure 3 on constatera le peu d’intérêt à utiliser un diagramme circulaire (ou « camembert »), en dehors de l’aspect coloré et tape à l’oeil.
7. Vers le tidyverse
On a vu la construction d’un graphique par la mise en place de couches sous ggplot2. Il faut cependant noter qu’on n’a fait qu’une très brève incursion dans ggplot2, plus intuitive qu’explicative d’ailleurs.
Pour avoir un rapide panorama des possibilités de ggplot2, on pourra profiter de cet exposé de Joseph Larmarange qui fournit aussi une webographie complémentaire.
À noter aussi (mais il y en a tellement d’autres) ce billet d’introduction à ggplot2 en anglais sur le site du statisticien Antoine Soetewey, Stats and R, que je viens (au 21 décembre 2020) de découvrir par hasard.
Mais la grammaire n’est là que pour nous aider à la bonne construction du graphique. Elle n’aide en rien à la construction du bon graphique.
Elle n’apporte rien concernant la pertinence du graphique pour le problème qu’il est censé éclairer ou poser.
Ainsi, le graphique s’inscrit dans un cycle de vie qui va du choix et de la constitution des données brutes (où dès l’abord on peut produire des biais) jusqu’à son interprétation lors de sa communication graphique :

Le cycle de vie des données selon Wickham
Hadley Wickham propose tout un ensemble de modules R (dont ggplot2) pour faciliter et fiabiliser chaque phase de ce cycle de vie, ce qu’il appelle le tidyverse, qu’on explorera peut-être un jour sur ce site.
———- La citation :
Allez, en clin d’oeil à Leland Wilkinson qui est un fondu de piano, une interprétation par Polina Osetinskaya de la transcription pour piano (par Alexandre Tharaud) du largo du concerto en ré mineur pour orgue BWV 596 de Bach, concerto pour orgue qui est lui-même la transcription du concerto n° 11 en ré mineur pour deux violons, violoncelle et cordes, RV. 565 de Vivaldi.
Quand c’est beau ? On transcrit !
Dernière modification: 21 décembre 2020
Établi: 16 octobre 2020